
Les sous-titres fermés sont un moyen efficace d’améliorer l’accessibilité, l’engagement et la rétention d’informations lors des présentations et des événements en direct.
Les sous-titres automatiques convertissent la parole en texte qui s'affiche à l'écran en temps réel dans la même langue que la parole. L'ASR - Reconnaissance Automatique de la Parole - est une forme d'intelligence artificielle utilisée pour produire ces transcriptions de phrases prononcées.
Taux d’erreur de mots
Pour évaluer la précision des sous-titres automatisés, la métrique la plus largement utilisée est le taux d’erreur de mots (WER). Celle-ci mesure le nombre d’erreurs dans la transcription automatisée par rapport aux mots réels prononcés par l’orateur. Essentiellement, elle fournit un moyen de déterminer dans quelle mesure le système automatisé convertit la parole en texte.
Par exemple, si 4 mots sur 100 sont incorrects, la précision serait de 96 %.
Le taux d’erreur de mots (WER) est une métrique utilisée pour mesurer la précision des sous-titres automatisés. Il aligne les séquences de mots correctement identifiées à un niveau granulaire avant de calculer le nombre total de corrections nécessaires pour aligner complètement les textes de référence et de transcription. Cela comprend l’identification des substitutions, des suppressions et des insertions. Le WER est ensuite calculé en divisant le nombre d’ajustements nécessaires par le nombre total de mots dans le texte de référence. En général, plus le WER est bas, plus le système de reconnaissance vocale est précis.
WER néglige la nature des erreurs
La mesure du taux d’erreur de mots (WER) peut être trompeuse car elle ne nous indique pas à quel point une certaine erreur est pertinente/ importante. Les erreurs simples, comme l’orthographe alternative du même mot (movable/moveable), ne sont pas souvent considérées comme des erreurs par le lecteur, tandis qu’une substitution (exemptions/essentials) peut être plus percutante.
Les chiffres du taux d’erreur de mots (WER), en particulier pour les systèmes de reconnaissance vocale à haute précision, peuvent être trompeurs et ne correspondent pas toujours aux perceptions humaines de la justesse. Pour les humains, les différences de niveaux de précision entre 90 % et 99 % sont souvent difficiles à distinguer.
| Transcription originale: | Sortie des sous-titres ASR: |
| Par exemple, je fais comme seulement une utilisation très limitée doit être faite des essentiels fourni, je souhaiterais approfondir un point particulier, je crains que j'appelle aux parlements d'État individuels de ratifier la convention uniquement après que le rôle de la Cour européenne de justice ait été clarifié pourrait avoir des effets très préjudiciables. | Par exemple, je souhaiterais également que l’utilisation des exemptions fournies soit très limitée, je voudrais approfondir un point particulier, je crains que le appel sur les parlements des États individuels pour ratifier la convention uniquement après que le rôle de la Cour européenne de justice ait été clarifié pourrait avoir des effets très préjudiciables. |
Interprefy's Taux d’erreur de mots perçu
Interprefy a développé une métrique propriétaire et spécifique à chaque langue pour la reconnaissance automatique de la parole (ASR) appelée Taux d’erreur perçu (WER). Cette métrique ne compte que les erreurs qui affectent la compréhension humaine du discours et non toutes les erreurs. Les erreurs perçues sont généralement inférieures au WER, parfois même jusqu’à 50 %. Un taux d’erreur perçu de 5 à 8 % est généralement à peine perceptible pour l’utilisateur.
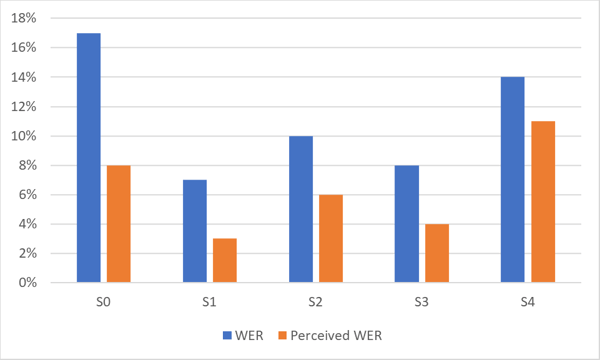
Le graphique ci‑dessous montre la différence entre le Taux d’erreur de mots (WER) et le Taux d’erreur perçu (WER) pour un système ASR très précis. Notez la différence de performance pour différents ensembles de données (S0‑S4) de la même langue.
Comme le montre le graphique, le taux d’erreur de mots perçu par les humains est souvent nettement meilleur que le taux d’erreur de mots statistique.
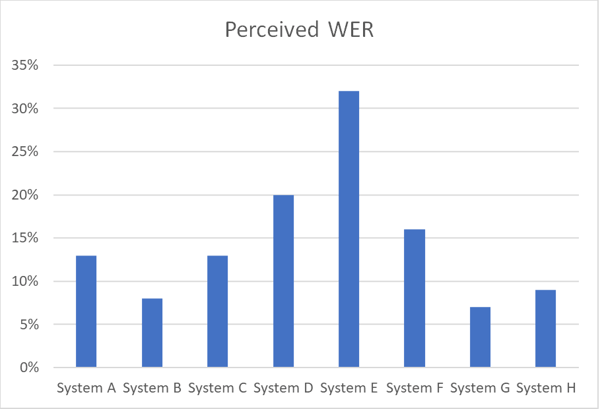
Le graphique ci-dessous illustre les différences de précision entre divers systèmes de reconnaissance automatique de la parole (ASR) travaillant sur le même jeu de données vocales dans une certaine langue en utilisant le taux d’erreur perçu (WER).
Facteurs clés pour obtenir des sous-titres fermés incroyablement précis
Il y a trois points clés à prendre en compte :
- Utilisez une solution de premier ordre : au lieu de choisir un moteur générique pour couvrir toutes les langues, optez pour un fournisseur qui utilise le meilleur moteur disponible pour chaque langue de votre événement.
- Optimisez le moteur : choisissez un fournisseur capable de compléter l'IA avec un dictionnaire sur mesure afin de garantir que les noms de marques, les noms inhabituels et les acronymes soient correctement capturés.
- Assurez-vous d’une entrée audio de haute qualité : si l’entrée audio est mauvaise, le système de reconnaissance vocale ne pourra pas atteindre une qualité de sortie satisfaisante. Veillez à ce que la parole soit capturée de manière forte et claire.